When Sequence Models Forget Important Steps: Decision MetaMamba
Modern reinforcement learning increasingly treats decision making as a sequence modeling problem. Instead of learning policies through environment interaction, offline RL models learn from past trajectories of states, actions, and rewards.
One influential approach is the Decision Transformer, which reframes RL as conditional sequence prediction. Recently, state-space models (SSMs) like Mamba have emerged as promising alternatives because they scale efficiently to long sequences.
But there is an overlooked problem.
Sequence models—both attention-based Transformers and selective SSMs like Mamba—can silently ignore important parts of a trajectory.
This is exactly the issue addressed by Decision MetaMamba.
The Hidden Weakness of Selective Sequence Models
Models such as Transformers and Mamba rely on mechanisms that selectively emphasize certain tokens while suppressing others.
For language tasks, this behavior is desirable. Words like “the” or “and” often carry little semantic information, so suppressing them helps the model focus.
However, reinforcement learning trajectories are different.
A trajectory contains structured information: State, Action, and Return-to-go (RTG)
If the model suppresses any of these components, it may lose essential information about the environment dynamics.
In practice, this problem appears clearly in Mamba’s selective scan mechanism.
Evidence from activation maps.
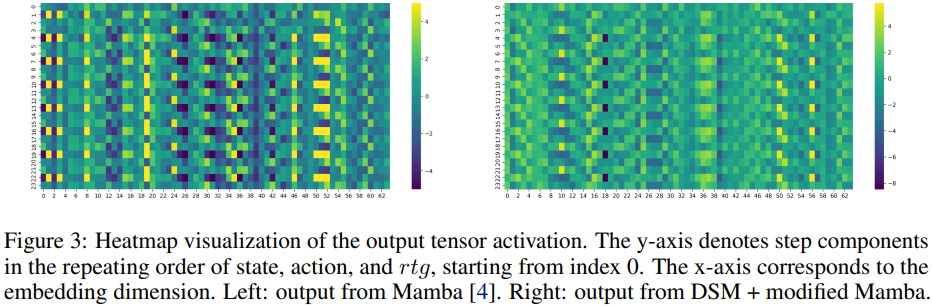
When visualizing Mamba’s activation patterns, something interesting appears:
Action tokens dominate the activations
State and RTG tokens sometimes nearly vanish
This means the model sometimes learns policies mostly from actions while ignoring states or rewards—clearly undesirable in RL.
The reason lies in Mamba’s gating mechanism, which can suppress already weak signals.
Fixing the Problem: Dense Sequence Mixer (DSM)
Decision MetaMamba introduces a simple but effective idea:
Mix the sequence locally before Mamba processes it.
This is done using a module called the Dense Sequence Mixer (DSM).
Instead of processing tokens independently across channels, DSM:
Takes a small window of neighboring tokens
Flattens and concatenates them
Applies a dense projection
This allows the model to jointly consider state, action, and return-to-go nearby time steps before the selective SSM operates.
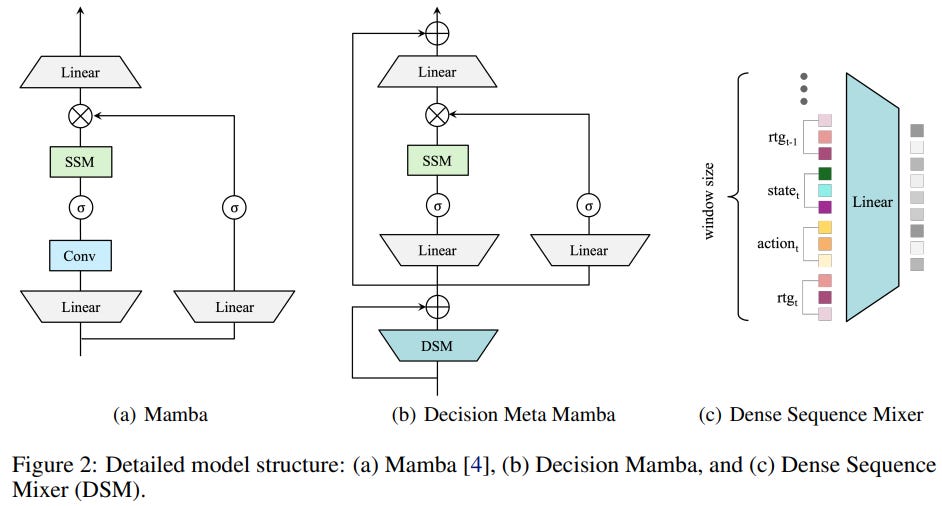
This simple change solves an important problem:
DSM prevents important information from being filtered out before the model can use it.
Decision MetaMamba: Local + Global Sequence Mixing
The resulting architecture is Decision MetaMamba (DMM).
The model combines two complementary components:
Local sequence mixer, DSM
Captures short-range dependencies such as:
- state transitions
- immediate action effects
- local trajectory patternsGlobal sequence mixer, Modified Mamba
Captures long-range dependencies across the trajectory.
Together they form a heterogeneous sequence mixing architecture:
This design allows the model to learn:
- local transition dynamics
- long-range decision dependencies
simultaneously.
Why This Helps: More Balanced Attention and Stronger Local Dynamics
One interesting finding from the paper is that the improvement is not purely architectural—it also changes how the model utilizes information in the trajectory.
To investigate this, we measured gradient norms with respect to each input component. The results reveal a clear imbalance in standard sequence models
Gradients for state and RTG are much smaller
The model tends to rely primarily on actions
This suggests that important contextual signals—especially state information—can be underutilized.
However, when the Dense Sequence Mixer (DSM) is introduced, the pattern changes:
Gradients for state and RTG increase
Contributions across inputs become more balanced
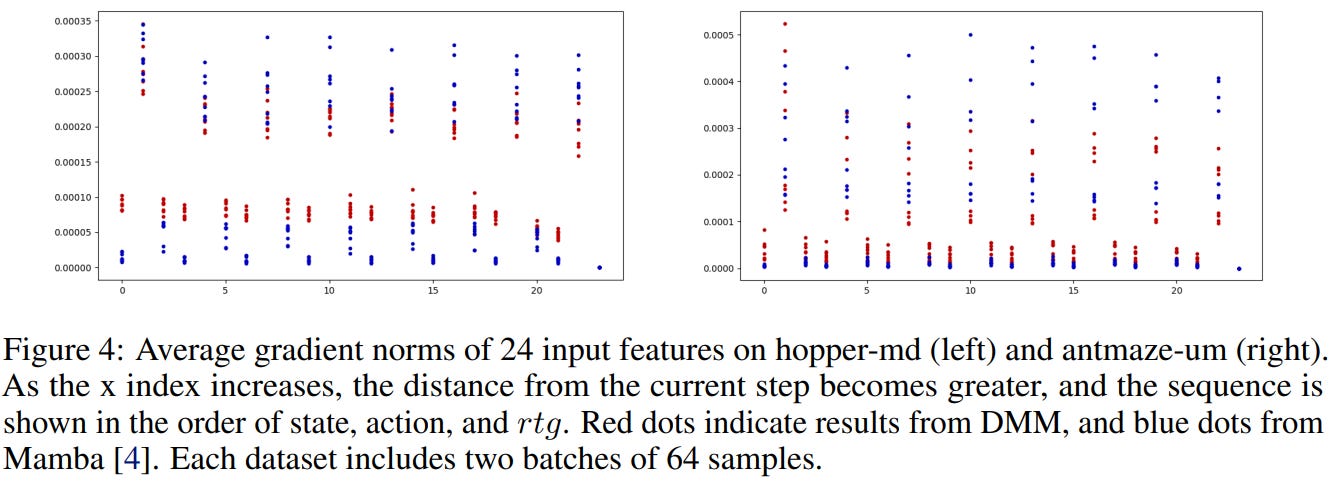
This indicates that the model begins to use the full trajectory information, rather than implicitly overfitting to actions alone.
Figure 4 also reveals another important pattern: inputs closer to the current timestep receive larger gradients, particularly the t-1 step.
This behavior aligns well with the Markov property in reinforcement learning, where the next state and optimal action depend most strongly on recent states and actions.
Standard attention mechanisms or selective SSMs do not explicitly encode this inductive bias.
In contrast, DSM implicitly encourages it by mixing nearby tokens before the global sequence modeling stage, allowing the model to better capture local transition dynamics.
From this perspective, Decision MetaMamba naturally decomposes sequence modeling into two complementary roles:
DSM → captures local dynamics between neighboring steps
Mamba → models long-range dependencies across the trajectory
By combining both, the model better reflects the structure of RL trajectories, where local transitions and long-term dependencies are both critical for decision making.
The Effect Becomes Clear in Sparse-Reward Problems
The most interesting result appears in sparse reward environments.
In these tasks:
- rewards are given only at the end
- important signals must propagate across long time horizons
This makes long-range reasoning essential.
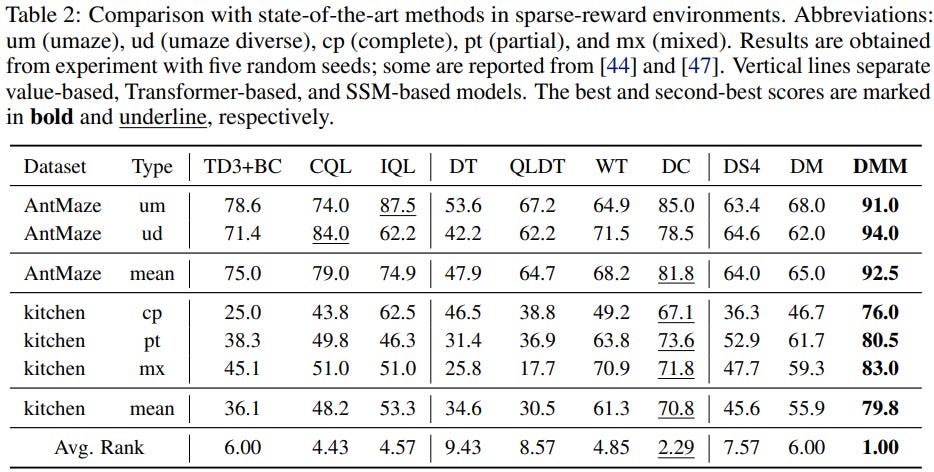
Decision MetaMamba performs particularly well here.
On benchmarks like AntMaze and Franka Kitchen, the model significantly outperforms previous methods.
For example:
+13.5 improvement on AntMaze
+18.5 improvement on Kitchen tasks
These environments require the model to infer long-term credit assignment, making them especially sensitive to information loss.
DSM helps preserve key signals from earlier steps, enabling better long-horizon reasoning.
Another Advantage: Efficiency
Despite improved performance, Decision MetaMamba remains efficient.
SSM-based architectures like Mamba already scale linearly with sequence length, unlike the quadratic complexity of attention.
Because DSM uses a small local window, the additional overhead is minimal.
The result is a model that is:
competitive with Transformer-based methods
efficient enough for robotics and edge deployment.
Takeaways
Decision MetaMamba highlights an important lesson:
Sequence models can accidentally ignore critical information.
In reinforcement learning trajectories, this is especially dangerous because every step can influence future outcomes.
By introducing a simple Dense Sequence Mixer, the model:
preserves local trajectory information
balances contributions of state, action, and reward
improves long-range reasoning
The result is a simple but surprisingly effective improvement to Mamba-based decision models.
If you want to explore the details, check out the paper:
Decision MetaMamba
https://arxiv.org/abs/2408.10517