Extending Tabular Foundation Models to Multimodal Data: Inside MultiModalPFN (CVPR 2026)
Tabular data is everywhere: finance, healthcare, marketing, and operations. Despite the rise of deep learning, traditional models like gradient boosting still dominate tabular machine learning.
However, modern datasets rarely contain only tables.
Medical datasets include images and metadata, e-commerce datasets combine text reviews and product attributes, and many real-world problems require reasoning across structured and unstructured data.
This raises a fundamental question:
Can we build a foundation model for tabular learning that also understands images and text?
Our recent work, MultiModalPFN (MMPFN)—accepted to CVPR 2026—explores exactly this idea by extending the tabular foundation model TabPFN into a multimodal learning system.
In this post, I’ll walk through the key ideas behind the model and some interesting insights we discovered while building it.
The Rise of Tabular Foundation Models
Recent work introduced TabPFN, a transformer trained on millions of synthetic tabular datasets.
Instead of training a new model for each dataset, TabPFN treats tabular prediction as amortized Bayesian inference:
During pretraining, it learns a prior over tabular data distributions.
At inference time, it solves a new tabular task in a single forward pass.
This makes TabPFN surprisingly powerful for small and medium datasets, where traditional deep learning models often struggle.
However, TabPFN has a limitation:
It only works on pure tabular data.
But real-world datasets often include images, text, or other modalities alongside tabular features.
This is the gap MultiModalPFN aims to fill.
The Core Idea: Treat Everything Like Tabular Data
The key idea of MultiModalPFN is simple but powerful:
Convert non-tabular modalities (images or text) into tabular-compatible tokens so that TabPFN can process everything together.
Instead of redesigning the entire architecture, we reuse the existing TabPFN backbone and only build a bridge between modalities.
The resulting architecture has three parts:
Per-modality encoders
A modality projector (our main contribution)
The TabPFN backbone
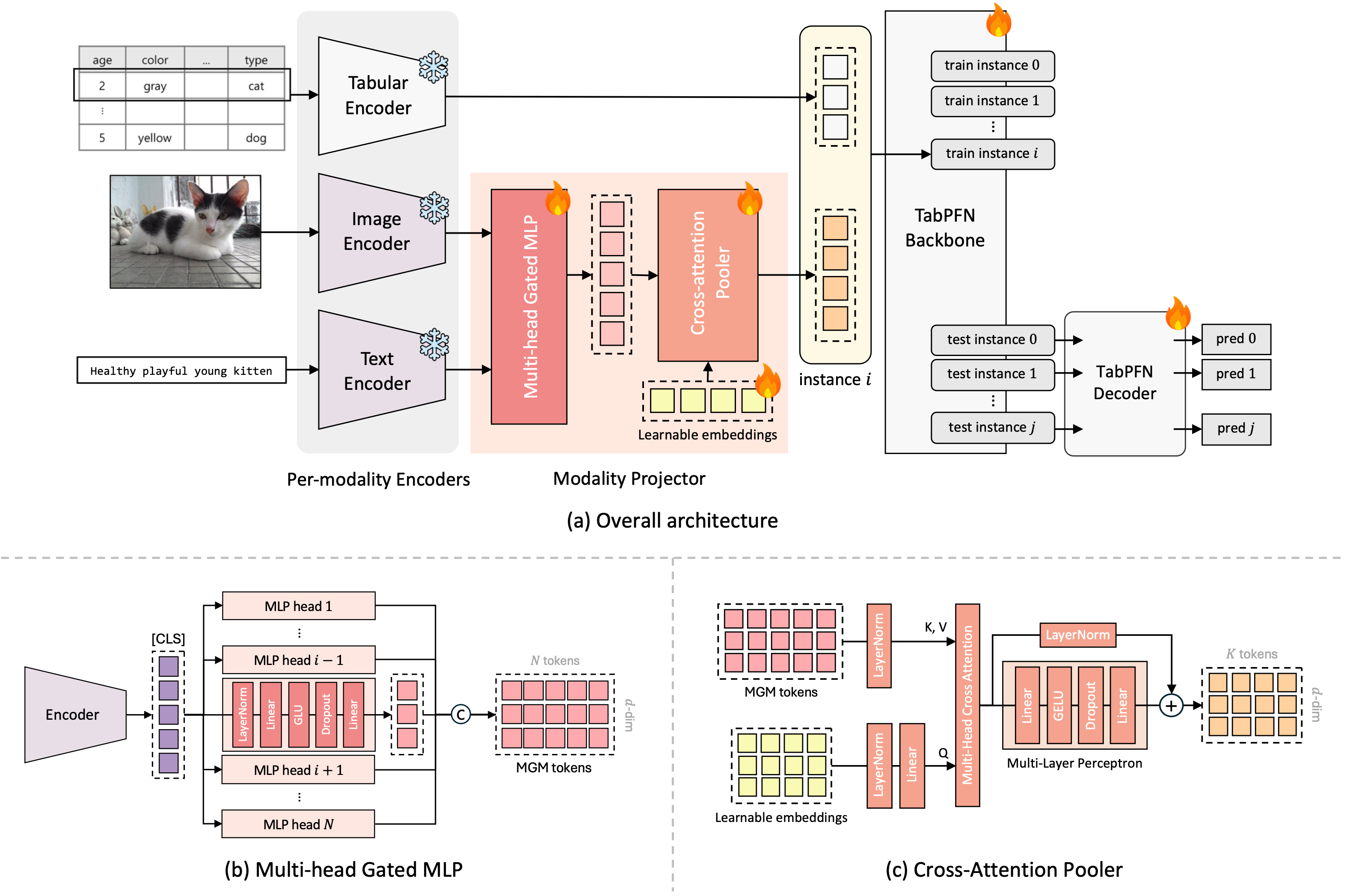
Images and text are first encoded with pretrained models.
Their representations are then projected into the same feature space as tabular tokens.
Once everything is in a compatible format, the TabPFN transformer processes them as if they were part of a single table.
A Subtle Problem: Over-Compressed Representations
Many multimodal systems use a single representation such as a CLS token from an image or text encoder.
But this introduces a problem.
A single embedding often over-compresses information from the original modality. Important details may disappear when everything is squeezed into one vector.
We address this using a module called Multi-head Gated MLP (MGM).
Multi-Head Feature Expansion
Instead of producing one embedding, MGM expands the representation into multiple tokens.
Each head learns to capture different aspects of the modality:
- texture or visual patterns from images
- semantic signals from text
- contextual cues relevant to tabular prediction
A gating mechanism then selects which features are useful.
This allows the model to extract diverse signals from non-tabular inputs.
Experiments show that expanding the representation into multiple tokens significantly improves performance compared with single-vector projections.
TabPFN Can Classify Images and Texts
We tried feeding only image embeddings into the TabPFN backbone.
The result?
Performance was within ~1% of a standard DINOv2 + MLP classifier.
This suggests something interesting:
A transformer trained purely on synthetic tabular data can still operate effectively as a classifier on image and text embeddings—once those embeddings are mapped into a tabular-like feature space.
This hints that tabular foundation models may be more general than we thought.
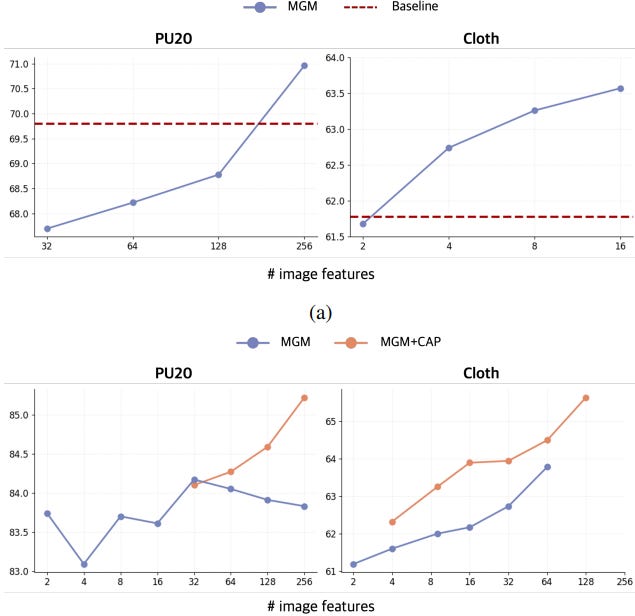
Another Hidden Issue: Attention Imbalance
Once we started adding many tokens from images or text, we discovered another surprising problem.
Transformers allocate attention across all tokens. If one modality contributes significantly more tokens, it may dominate the attention budget.
In simple terms:
If image tokens greatly outnumber tabular tokens, the model may ignore the tabular features entirely.
We call this phenomenon attention imbalance.
The paper shows that expected attention mass roughly scales with token count
Meaning that if the number of image tokens becomes large, attention shifts toward them even if their quality is similar to tabular tokens.
This phenomenon appears more prominently only when the amount of information in the tabular and non-tabular data is similar and distinct.
Balancing Modalities with Cross-Attention Pooling
To address this issue, we introduce Cross-Attention Pooler (CAP).
Instead of feeding all modality tokens directly into the backbone, CAP compresses them into a small, fixed number of representative tokens.
The mechanism works as follows:
Learn a small set of query vectors
Let them attend to the expanded tokens
Produce a compact summary representation
This achieves two goals:
- preserves rich modality information
- prevents token imbalance from overwhelming the transformer
Does It Actually Work?
We evaluated MultiModalPFN on several multimodal datasets including:
- medical imaging datasets
- tabular-text benchmarks
- real-world multimodal datasets like PetFinder
Across nearly all datasets, MMPFN outperformed existing multimodal tabular models.
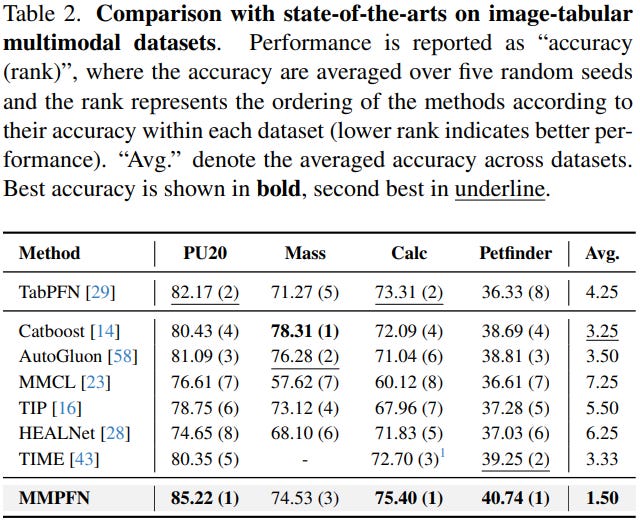
The model consistently ranked first across most benchmarks.
Robust in Low-Data Regimes
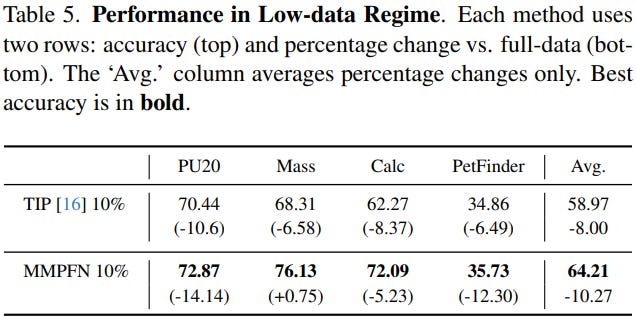
Another key advantage of TabPFN is its performance with small datasets.
Because the model already learned strong priors during pretraining, it adapts well even when only 10% of the data is available.
In experiments, MMPFN still outperformed strong baselines under these low-data conditions.
This is particularly important for domains like healthcare, scientific datasets and industrial applications where labeled data is limited.
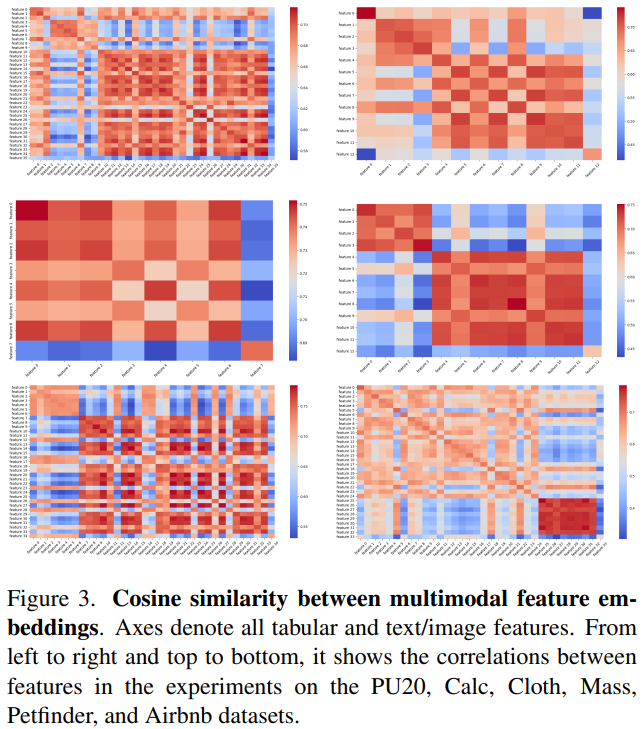
Correlations between Modalities
Figure 3 further illustrates how Multimodal PFN captures relationships across modalities. The cosine similarity matrix shows that features from tabular, text, and image inputs are embedded into a shared representation space rather than forming completely separate modality-specific clusters. Notably, certain cross-modal feature pairs exhibit high similarity, indicating that the model learns meaningful associations between different modalities. This suggests that Multimodal PFN does not treat modalities independently, but instead aligns them within a unified feature space, enabling it to capture multimodal dependencies.
Scaling with More Modalities
Finally, we tested what happens when additional modalities are introduced.
On the PetFinder dataset:
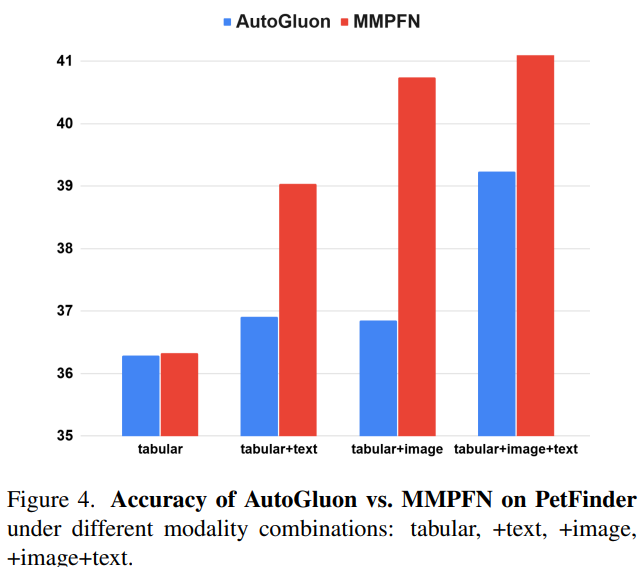
Performance increases as modalities are added, showing that MMPFN can effectively combine complementary signals.
Takeaways
MultiModalPFN demonstrates a simple but powerful idea:
Instead of redesigning multimodal architectures from scratch, extend a tabular foundation model by converting other modalities into tabular-compatible representations.
Code is available here:
https://github.com/too-z/MultiModalPFN
If you’re interested in multimodal tabular learning or TabPFN-style models, the paper provides much deeper technical details.
https://arxiv.org/abs/2602.20223